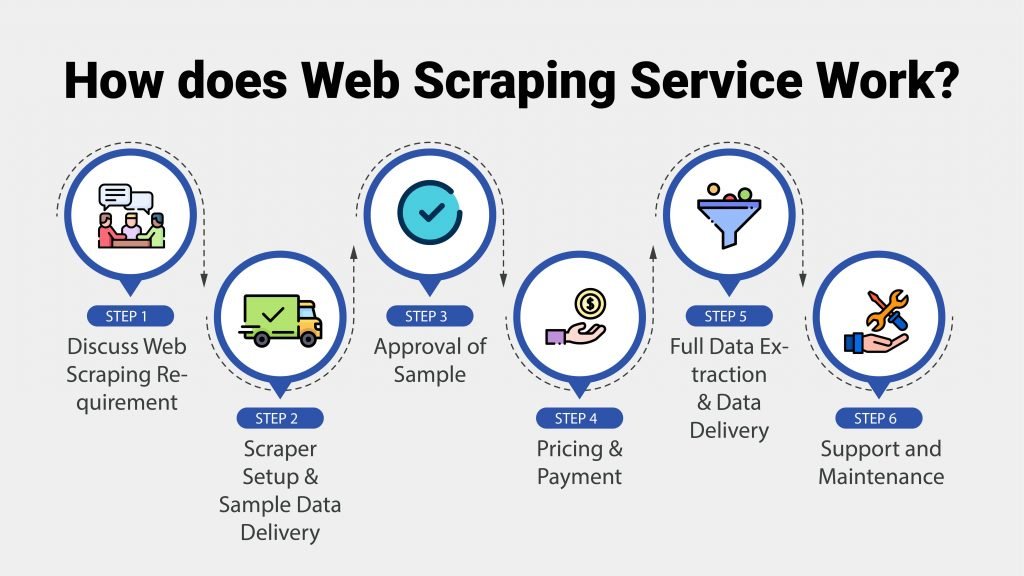
During this time around we acquired a remarkable amount of experience as well as proficiency in internet information extraction. Web scuffing is everything about the information - the information areas you wish to extract from particular sites. With scratching you typically understand the target websites, you may not know the details web page Links, but you recognize the domain names a minimum of. One helpful plan for web scraping that you can locate in Python's conventional library is urllib, which has devices for working with URLs. Particularly, the urllib.request module has a feature called urlopen() that you can use to open up a link within a program. The Internet hosts perhaps the greatest resource of details on the planet.
- Find out web scuffing with Ruby with this step-by-step tutorial.
- In a very first exercise, we will certainly download a single website from "The Guardian" and also essence message together with appropriate metadata such as the article day.
- Yet after reading this article, we wish you'll be clear concerning the context, the factors of distinction, as well as the use of both.
- Their functionality varies in degrees, and you can choose from the ones offered, depending on whichever matches your standards for information need the most.
- This is something that deserves its very own article, however, for now we can do rather a lot.
- Generally, this is a JSON data, however it can also be saved in other styles like a succeed spreadsheet or a CSV file.
They check out websites as well as gather all the appropriate details that indexes them as well as look for all links in the related pages. A lot of individuals do not comprehend the difference between data scraping and also information crawling. This ambiguity results in misunderstandings as to what service a client desires.
Use An Html Parser For Web Scraping In Python
That's a wonderful beginning, yet there's a great deal of fun things you can do with this spider. That ought to be enough to get you believing as well as trying out. If you require more info on Scrapy, look into Scrapy's main docs.
What is the distinction in between creeping and browsing?
A crawler is a computer program that checks records online instantly. Spiders are mostly programmed to ensure that searching is automated for repetitive actions. Search engines make use of spiders most frequently to surf the Internet as well as create an index.
Whether or not you are anticipating an outright or family member link can be stored as a home of the Site item. Obtain full access to Web Scuffing with Python, 2nd Edition and 60K+ other titles, with a free 10-day trial of O'Reilly. Components can be removed in XML objects with XPATH-expressions. Initially, ensure your working directory is the information directory we offered the workouts. This is where you can add your API secret which will connect to your Browserless account as well as enable you to run your script with Browserless.
Build An Internet Crawler
" Creeping permits us to take disorganized, scattered data from multiple sources as well as gather it in one place and also make it structured," says Marcin. " If you have several web sites regulated by different entities, you can integrate all of it right into one feed. Information scratching and also information crawling relate techniques to make it perplexing for you. However after reading this short article, we wish you'll be clear about the context, the factors of difference, and the use of both. Information scratching services can carry out tasks that are not able to be completed by software program crawling devices, such as implementing javascript, sending information formats, resisting robotics, and so on.
Internet scuffing is basically drawing out information from web sites in an automated manner. In this write-up, read an explanation of the differences in between internet scuffing and also internet crawling. To extract the data, the information spider drills deep into the Net. To find out what relates to your pursuit, think of crawlers or crawlers scavenging through the Internet.
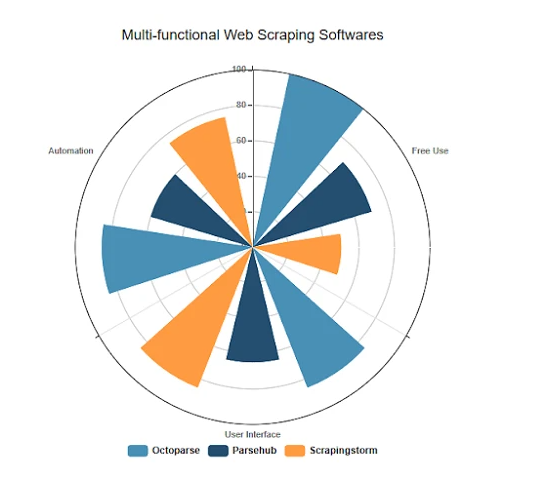
What Is A Worker In Nodejs?
Although the applications of internet spiders are nearly countless, large scalable spiders have a tendency to fall into one of several patterns. By finding out these patterns and recognizing the situations they relate to, you can greatly boost the maintainability and also toughness of your internet crawlers. Currently we can repeat over all URLs of tag summary pages, to gather more/all links to posts marked with Angela Merkel. We iterate with a for-loop over all URLs and also add results from each solitary link to a vector of all links. Now, web links includes a checklist of 20 links to solitary write-ups marked with Angela Merkel. HTML/ XML items are a structured representation of HTML/ XML resource code, which enables to draw out single components (headlines e.g.
- The-- sup flag is used to produce a brand-new task with an OTP skeletal system, consisting of the supervision tree.
- Why refrain from doing it the other way around, gathering all subjects from one site, and after that all topics from the following internet site?
- The https://web-scraping-services.s3.us-east-1.amazonaws.com/Web-Scraping-Services/api-integrations/internet-scraping-vs-web-crawling-whats-the.html demand for internet data crawling has gotten on the increase in the past couple of years.
- Information scratching is very important for a business, whether to obtain consumers or service and earnings growth.
As the internet crawler analyzes and also brings the link, it will find new links embedded in the page. To choose which is ideal for your requirements or exactly how to incorporate them for your internet scraping project, you require to recognize the distinctions in between web scraping and also web crawling. Their functionality differs in levels, and you can pick from the ones readily available, depending upon whichever matches your standards for information demand one of the most. Nonetheless, only a few handle to go far in the information sector, the factor being that the job of an effective web crawler is not as simple one. Data scuffing has actually become the ultimate device for organization growth over the last years.
Free Chrome proxy supervisor expansion that works with any type of proxy service provider.
https://maps.google.com/maps?saddr=340%20King%20St%20E%204th%20floor%2C%20Toronto%2C%20ON%20M5A%201K8%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
If you have actually ever duplicated and also pasted web content from a web site into a different location, you are doing an extremely manual version of data scuffing. In this short article, we will certainly be utilizing software application applications to do the data scratching for us. Using one of the strategies or devices explained formerly, develop a documents that uses a vibrant web site query to import the information of items detailed on your site. Attempt finding a checklist of beneficial contacts on Twitter, and import the information utilizing data scratching. This will offer you a preference of just how the procedure can match your daily job. FeedOptimiseoffers a variety of information scraping and also information feed services, which you can learn about at their site.
The humble guide to building an asset library - befores & afters
The humble guide to building an asset library.
Posted: Tue, 11 Jul 2023 11:15:42 GMT [source]
What is the distinction between junking and creeping?
Web scratching purposes to extract the data on website, and internet creeping purposes to index and also find web pages. Web crawling entails adhering to web links permanently based on links. In contrast, web scratching suggests creating a program computing that can stealthily accumulate data from numerous internet sites.